


The "Terza" Wave....

“History never repeats itself, but it rhymes”
The rhymes of the bard are drowned by chatter of GPT, the black swan has been sighted, a reference my good friend Partha Ranganathan called out last year at Stanford. A moment I have been waiting for 20 years and in reflection feels like I have been in training for this moment.....
A black swan moment has three attributes - its an outlier, has extreme 'impact' and we humans connect the dots after the fact. Terza (three) is past, present and future. Terza vertices of a triangle, and a perfect storm typically three colluding events. Terza is number three in Italian.
2023 and ChatGPT is perhaps like events that happened in 1998 (see below) that caused a perfect storm. New workloads, New platforms and New business models. The enabler - vision (diffusion , SAM ) models and NLP (transformers ), we have two parallel AI trains that are taking us past the AI inflection point that even Google (the source of key ideas) did not realize the bend in the exponentials of adoption. We have landed on the third (Terza) wave of modern computing. The entire stack will get re-engineered and I am reminded once more about this shift from the past.
To support the 'entire stack will be re-engineered' claims above, allow me to take the history rhymes analogy to build the collective intuition on this thesis.
Going back 20 years (Circa 2001-2003), we faced a similar 'black swan' moment. At that time it was the overnight shift from proprietary Unix 'Scale-up' platforms (Solaris, HPUX, AIX) and programming models to distributed systems or shift from coherent shared memory to distributed memory. Search and in general SaaS in effect was a distributed memory (and data) programming model problem that was solved at the application tier. It was not that obvious and potentially ubiquitous application or workload model back in 2003. By 2013 (10 years) it was a settled matter.
The Tsunami wave that led to that was built on two technologies (processors and operating systems) and an economic downward shift (dot.com bubble) accelerated the business model shift (Capex to Opex) as well. One was Linux maturing over Solaris/Unix as the Software infrastructure platform and multi-core x86 winning over multi-core RISC. That whole transition occurred between 1995 and 2002.

source: Tech Shifts Talk at Intel
In 1995, Intel was lagging on processors for infrastructure ( it was the peak of 64-bit RISC machines from Sun, HP, MIPS/SGI and Power). Intel was using BiCMOS (Pentium) till mid 1990s and was behind the CMOS tech curve (IBM, TI..) as I have written here - (Intelligrated). Between 1998 and 2002, Intel prioritized engineering the transistor, postponed metal transition (Cu) until later (side note: We [SPARC @ TI] followed IBM's lead on copper metal transition and industry norm for FOM improvements. At Intel, fab dictated the PDK the the CPU designers should use (other way around with us). The chart below shows how Intel came back from behind.

In that period (1995-2002), Open Source (linux) reaches an inflection point.

Source: Wikipedia.
By 1995, Linux was expanding to other ISAs (SPARC and PPC), Redhat going public in 1999, and release of 2.4 was a key marker for its maturity and adoption by then internet companies as the operating system for their infrastructure.
Side note: At the same time in 1998 - three companies amongst many were founded. VMware, Google and Equinix. We will get back to this later in this blog.
Linux gaining momentum thereby sedimenting the value of operating systems was the perfect setup for the shift.

Tectonic shifts are punctuated by Margin vs Market share dilemma with incumbents. OEMS of those days (HPE, IBM, Sun) were beholden to their customer base and their workload like Oracle (shared everything database) that prefered SMPs and thus missed the shift. While NUMA was a way to extend the scale of shared memory platforms, the 'enterprise app' programmers were beholden to the shared memory (SMP) model.
At the same time Google, Amazon, Akamai and Yahoo decided to take a clean sheet and work backwards from application or use cases (SaaS) and build systems for massive scale problems like CDN, search, shopping, social media. The marginal cost and sedimentation of value at work, which is again in play 20 years later.
Looking further back, the Scale-up era was initiated by the "Attack of the killer microprocessors (RISC), Unix (then open source) and a recession (1982 ). This has occurred twice in the past, and a thesis is we are onto the third (i.e Terza).
Between 1998 and 2008 (origins of EC2 and S3 at AWS) , the entire infrastructure for the new use cases was flipped over. With cloud formation, we went from 3-Tier to SaaS. The era of distributed 'memory' systems was punctuated by CAP theorem (Eric Brewer), strongly consistent to variable consistency models for data (Cassandra), reliable by design vs recovery oriented computing (Dave Patterson/Berkeley), the distributed computing manifesto (Werner vogels).
An interesting side note is the emergence of virtualization at the peak of scalable shared memory platforms whose value was eventually captured as a pure software play (VMware) and a free or open version (marginal cost going to zero), enabled the cloud.
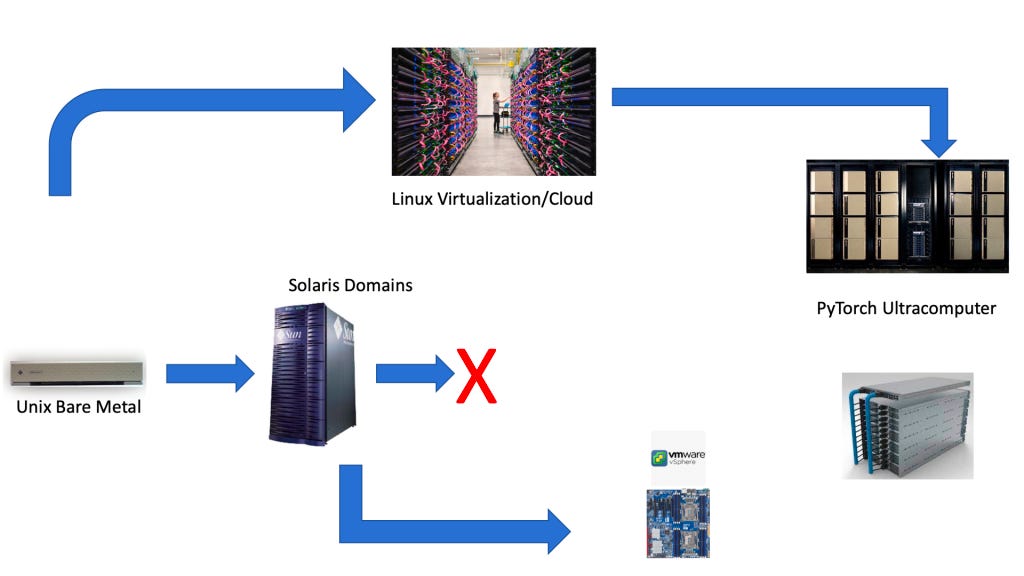
Platform Transitions
Back to the future
A down market for SaaS, the rise of AI (emergent use case) driving the need for new infrastructure, the rise of xPU (Nvidia-GPU, Google - TPU) and inadequacy of current cloud providers to both satisfy the demand and meet the cost, performance and data sovereignty needs. The same margin vs market share dilemma is being played out (Google vs ChatGPT-MSFT) that is going to give rise to new players (a few upstarts - OpenAI, Cohere, Anthropic, Stability, character, adept....) that will take on the Goliaths with a new David strategy. They are going to drive the new stack. Cost of compute is their #1 problem as witnessed by their capital raise of millions (as opposed to cost of customer acquisition in the early SaaS era).
The rise of the xPU. The past 6 months, we see the fortunes of Nvidia rise meteorically while Google has been working with TPUs for last 7+ years along with more than $2B of venture capital investments made for various AI silicon all the way from the large (Sambanova, Cerebras, Graphcore) to medium (Habana) and a smattering of others differentiating on cost, power and form factors and end deployment models. While Nvidia GPU and Google TPU are leading the pack in terms of deployment scale, the game has begun, but consolidating fast.
At scale, Inferencing dominates the total processing cycles (4:1) and inferencing can be done across a range of hardware solutions from CPU to xPUs, demanding price/performance or rapid commoditization of cost. Training is dominated by accelerators or performance worth the price design point. Inferencing at scale is compute #1, memory #2, network #3, Training is all about the Network #1, Memory #2 and then compute #3, Inverted model relative to serving. Architecturally, it's becoming a CPU + xPU silicon duo esp when it comes to serving / inferencing whereas Training is GPU first and then CPU. The ground truth here is CPUs and the huge software infrastructure are here to stay and serve a well understood purpose. The system design is once again constrained by memory model and its scale and additional compute ( linear algebra). The ratio of compute to memory and coherency vs consistency are the tradeoffs while keeping programming model simple. I distinguish coherency vs consistency to call out hardware based SMP (1-4 sockets) vs combination of hardware and software with variable consistency to meet the demands of scale vs resilience vs performance for the new serving and training workloads.
That is driving the system architectural push to a dual network, largely to bring compute and memory closer ("memory consistent"). In the case of Google their OCS and case of Nvidia its NVlink and other industry initiatives like CXL, including custom designs like in Dojo. The recognition here is base system needs for 10x-100x higher bisection bandwidth driven by large models touching a large chunk of memory (100s TB to PB perhaps) with associated compute. The need for a new memory model between hardware based coherence and application software driven coherent i.e distributed memory - I term it as 'consistent memory'.
This bifurcates the networking model of the past 20 years which led to success of ethernet as a flat (CLOS) single type to a two level network as memory has to be accessible for a given span of compute (defined by training and serving clusters). A high bandwidth and perhaps lower latency 'local network' that is perhaps spanning an aisle like the Dojo or the Google TPU cluster or Nvidia SuperPOD and ethernet for its ubiquity and traditional networking needs e.g. storage.
Finally, Linux and perhaps Unix system calls were the 'API' between the application developer and their chosen framework, we have now moved one level up to have the graph model and PyTorch/Tensorflow/cuDNN as the API contract between the developer and underlying infrastructure. In this case like Linux sedimented the value of operating systems, an open source framework will win (e.g. PyTorch). Revisiting the key elements of the stack...

The visual above is an over-simplified view of the evolving layers of the infrastructure stack. but the point is each one of these boxes resulted in new companies or companies re-engineering the entire stack. While one cannot predict the end state, the change event has happened and the race is it on to build the best Open AI Cloud (not be confused by OpenAI or Cloud).
Finally onto the new new business models - like the transition from Capex to Opex to _______(left as an exercise to the reader).
In closing......
The new infrastructure stack will be driven by new memory programming model (coherent, distributed to now consistent), the API and unit of workload defined by run time systems like Unix, VMs and now models to finally exploit Instruction level parallel (ILP), to threading (TLP) to now memory/data level parallelism (MLP).

At the same time the business models also have evolved at various layers as depicted by the visual below. In 2023, are we at 1998 (beginning) or 2003 (peak) of transition - cannot say - but we are somewhere in that similar time scale of transitions.

1998 was a eventful year.
launch of lowest cost Unix Workstations and Server ($1K) - Ultra 5
Launch of more scalable SMP (E10K)
Linux: IPO of Redhat
0.18uM CMOS (Coppertone) process from Intel (getting ahead in CMOS tech)
Founding of VMware, Google and Equinix
Amazon's distributed computing manifesto
Windows 98
Reference to Terms in this blog:
UMA: Uniform Memory Architecture
NUMA: Non-Uniform Memory Architecture:
UNA: Uniform Network Architecture
NUNA: Non-Uniform Network Architecture.
Scale-UP: Shared (Coherent) Memory Systems or Programming Model
Scale-Out: Distributed Systems i.e. memory across nodes are not coherent and communication is via IP or Infiniband or any non-coherent network fabric
Scale-in: New term introduced. A hybrid between Scale-UP and Scale-out.